Analyzing the BW data dictionary in Python

Reading data from Hana into Python and analyzing BW objects in Python
Hey there! Although I haven’t written about it, I continued my learning journey in my self hosted BW/4 system. In this post I will connect my favorite Data Science tool, Python, with BW/4’s underlying database HANA. I will read out the metadata describing the data objects I have created and quickly visualize them to show you my progress. This can come in handy when we want to analyze the data model in our BW/4 platform e.g. the re-usage of InfoObjects, i.e. MasterData.
How to connect Python to Hana
To connect to the Hana database and query data you will need the hdblci package. It follows the known DBAPI standards in python. Often BW/4 systems will have more than one tenant available on separate ports. To find out the correct port instead of trying them all out you can query SYS.M_SERVICES View from your tenant database. See my first post on how to do this with the hdbsql command line interface or simply use eclipse.
For my sap cloud appliance installation 30241 was the correct result. I could have also gotten this form the SAP Cloud Appliance Web Console. 
With the following python code you can connect to the database. Note that I use a .env file to hide my username and password. Of course it would also be possible to assign the username and password directly. The address is dynamic, since this makes hosting a bit cheaper, and hence has to be changed after each suspension.
from hdbcli import dbapi
from dotenv import load_dotenv
import os
import pandas as pd
load_dotenv(".env")
# find correct port using MSERVICE query
#
conn = dbapi.connect(
address='23.100.7.181',
port=30241, #
user=os.getenv("USERNAME"),
password=os.getenv("PASSWORD"),
database='HDB'
)
cursor = conn.cursor()
Connect to the HANA database
Querying the internal data dictionary tables
I want to query all Advanced Data Storage objects, the main data persistency object in BW/4, and InfoObjects, the characteristics or dimensions; their relation and describing texts.
Therefore I need the following tables:
- rsdiobj: Directory of InfoObjects
- rsdiobjt: Describing texts of InfoObjects
- rsoadso: Directory of ADSOs
- rsoadsot: Describing texts of ADSOs
- rsoobjxref: Directory of ADSOs
An overview of important internal BW/4 tables is provided for example by sap4tech.
I restrict the select of rsoobjxref to Objects of type adso TLOGO = ‘ADSO’ and only query active objects and texts in English OBJVERS=’A’ AND LANGU = ‘EN’.
Then the query looks for example follows. The python f-string notation provides a neat way to write dynamic queries. df.head returns the first five rows of the query.
table = 'RSOOBJXREF'
tlogo = 'ADSO'
objvers = 'A'
query = f"SELECT * FROM {table} WHERE TLOGO = '{tlogo}' AND OBJVERS = '{objvers}' "
df = pd.read_sql_query(query, conn)
df.head()
The resulting data frame has in my instance 1488 rows and looks as follows:
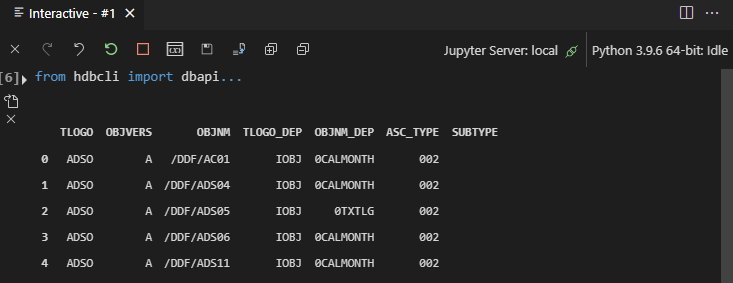
- TLOGO is the object type of the independent object, it only contains ADSO
- OBJVERS is the version of the object, I restricted it to A for active
- OBJNM is the name of the ADSO
- TLOGO_DEP is the object type of the dependent object
- OBJNM_DEP is the name of the dependent object
- ASC_TYPE is the association type according to SE80.co.uk, not quite sure what it means but all values are ‘002’ in my case
- SUBTYPE is a Subtype of TLOGO type and contains no values
Besides InfoObjects, I also have areas as dependent objects, since I am only interested in InfoObjects for the moment I filter on IOBJ. I created all my InfoObjects in the Z namespace meaning the first character of the OBJN_DEP is Z. I am not interested in the SAP BW BI content which is shipped with the BW/4, hence I also filter for the Z namespace. I can use the returned object names to only query the descriptions I need.
#Filter on InfoObjects and namespace Z
df = df[(df["TLOGO_DEP"]=="IOBJ" )& (df["OBJNM_DEP"].str[0]=="Z") ]
# get names of filtered InfoObjects from data frame above as string
c_iobj = str(tuple(df["OBJNM_DEP"].tolist()))
#filter by language = E (internal 1 char code for english)
langu = 'E'
#construct query
query = f"SELECT * FROM RSDIOBJT WHERE IOBJNM IN {c_iobj} AND LANGU = '{langu}' AND OBJVERS = '{objvers}'"
df_iobjt= pd.read_sql_query(query, conn)
#join the short description column using the the dependent object name in df and the IOBJNM in df_iobjt
df = df.merge( df_iobjt.loc[:,("IOBJNM","TXTSH")], left_on="OBJNM_DEP", right_on = "IOBJNM", how="left")
This results in all the InfoObjects and the two ADSOs I have created 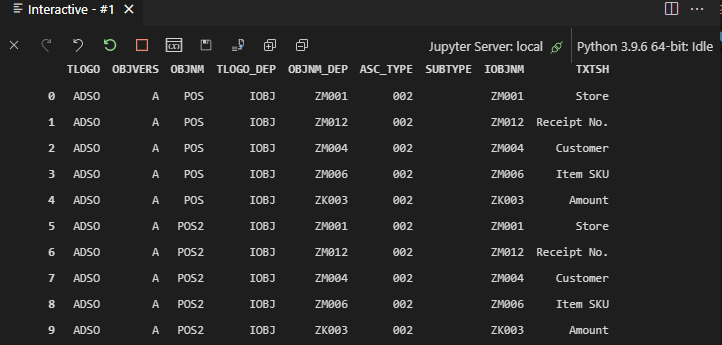
Now I visualize the data frame as a network graph. This will make it really easy to see which Dimensions are related to which persistency objects. This can be very helpful e.g. when you want to analyze the re-use of data and find patterns within your platform.
import networkx as nx
from matplotlib import pyplot as plt
#initialize grap
G = nx.Graph()
G = nx.from_pandas_edgelist(df,'OBJNM', 'TXTSH')
#draw graph
plt = plt.figure(figsize=(10,8))
nx.draw_circular(G, with_labels=True,
node_color=["red","green","green","green","green","green","red"],
node_size = [1200,600,600,600,600,600,1200])
We see that all InfoObjects (in green) are used in both of the ADSOs (red).
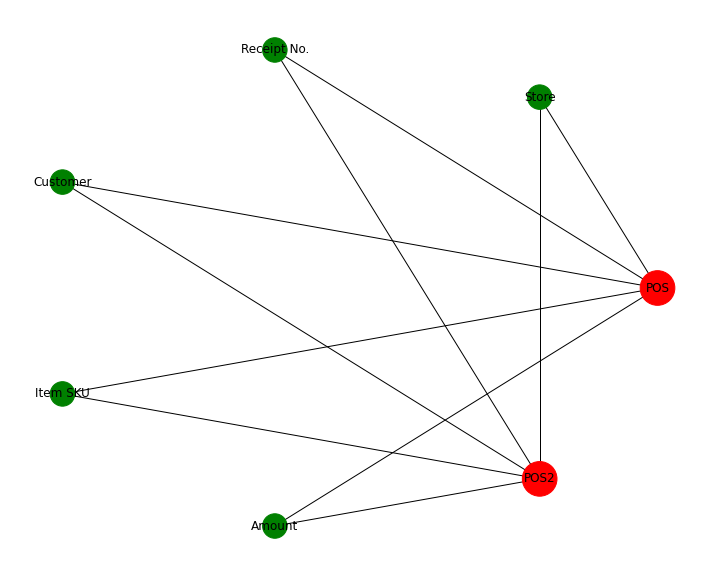
Conclusion
Querying the internal data dictionary tables can help to understand the structure of the BW/4. These tables can be used to highlight relations and analyze how much data is reused. They can also be used to surface information for users without backend access. This can be done e.g. by building a data catalog showing the relations between objects and even their lineage. In my minimal example the results where not that surprising but on huge production systems they can tell you a lot about how integrated your data warehouse actually is.
